こんにちは。渡辺です。
これまでprint()関数を使って、画面に文字を出力させることを学習しました。
今回は、これで日本語を表示させてみます。
まずは、あなたの名前をPythonに表示させてみましょう。
編集人も自分の名前でやってみます。
print(‘渡辺龍一郎’)
これで、「Run」メニューの「Run ‘study000’」コマンドで実行してみます。
その結果は、、、

何とprint()文に指定した自分の名前はどこへやら。エラーメッセージが出ました。
エラーメッセージの意味は?
英語で書かれていますが、「Syntax Error」というのは文法が違うということです。
コンピュータ言語は、コンピュータに実行させるため、曖昧さがなく厳密な文法で作られています。
ちょっとでも単語の打ち間違いがあったり、指定すべき情報が誤っていたりすると、このエラーに出会うことになります。
実は、コンピュータは日本語を扱うのがやや苦手なのです。
というのも、英語は0から9までの数字、シンプルな形で26文字だけのアルファベット(大文字と小文字で52文字)、#とか%とかのわずかな記号しかありません。
もし全部の文字に通し番号を振ったとして、100種類くらいで全部の文字が表現できます。
この文字毎に割り振った通し番号を「文字コード」といいます。
ところが、数千もの漢字やビジネスで使われる記号なども含むと、日本語で扱う文字は1万を超えます。形もけっこう複雑です。
ということで、漢字を扱うときは、英語だけじゃなくて、日本語文字のコードも扱いますよ、と事前にコンピュータに伝えなくてはいけません。

漢字を扱うお作法
プログラム中で漢字を使うときは、以下の記号で、プログラムの冒頭で、英語以外の文字コードを扱いますよ、ということをコンピュータに伝えます。
# coding: utf-8
さっそく、このコードを先頭に入れてみましょう。
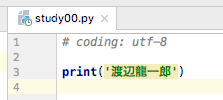
再度、「Run」メニューの「Run ‘study000’」コマンドで実行してみます。
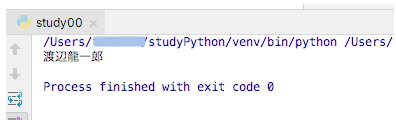
画面下部の出力を見ると、今度はめでたく、漢字の名前を表示してくれました。
日本語表示のややこしい歴史
以下は年寄りの茶飲み話として、余力があれば読んでみてください。
今回は、Macやスマホなどでよく使われている、UNICODE(ユニコード)という文字コードを使うということで、UTF-8を指定しました。
ところが、昔から各コンピュータメーカーでそれぞれが独自に日本語のコードを割り振ったり、それを日本工業規格(JIS)で一本化しようとJIS規格ができたり、それをまたあちこちで勝手に改良したりで、コンピュータの世界では、実はいくつもの漢字コードがあります。
Windowsパソコンでは、JIS規格をベースにしたシフトJISという漢字コードを使っています。
そのため、シンプルなテキストファイルとかだと、Windowsで作ったものをスマホで読もうとすると文字化けする場合があります。
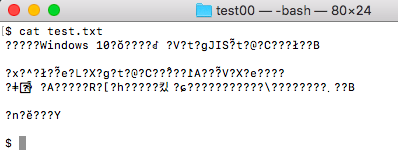
(注記: Macのテキストエディットは文字コードを自動判別するようで、きちんと読み込んでくれました)。
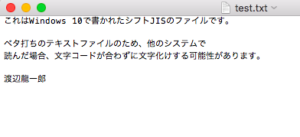
他のプログラミング言語だと、いちいちプログラムを書く人(=プログラマー)が文字コードを気にしなくても勝手に判断してよしなに取り計らってくれるものもありますが、Pythonは爬虫類のせいか(?)、そこまで優しくありません。
逆にいうと、それだけ柔軟性が高いということでもありますが。
<今日の要点ノート>
プログラム中で日本語を扱う時は、プログラムの冒頭に文字コードを指定する。たとえばスマホでよく使うUNICODEであれば、# coding: utf-8 と書く。複数の日本語コードがあるので注意。







コメント